Introduction: A New Era in Pharmaceutical Formulation
Over the past decade, Artificial intelligence (AI) has rapidly evolved from a trendy jargon to a cornerstone of pharma R&D over the past decade. It is no secret to most professionals in the pharma industry how AI has revolutionized the drug discovery process and the execution of clinical trials. However, the application of AI algorithm analyzing pharmaceutical formulation data in real-time lab environments.in formulation development, the sophisticated art and science of blending APIs with excipients to produce safe, stable, efficacious, and manufacturable dosage forms, is still an unfolding story. The Future of AI in pharmaceutical formulation isn’t just about automation, it’s about amplifying the formulator’s mind, accelerating innovation, and reshaping what’s scientifically possible.
This article unpacks how AI is stepping beyond the theoretical and into practical use cases within pharmaceutical formulation. With an emphasis on excipient selection, predictive dissolution modelling, and quality-by-design (QbD) strategies, this article is targeted at mid-level to expert professionals looking to stay ahead in an evolving regulatory and technological landscape.
1. Excipient Selection in the Age of AI: Data Replaces Guesswork
1.1 The Complexity Behind Excipients
A mantra well-known to Formulators: the appropriate excipient choice is not determined by flowability or compressibility alone. The perfect fit is a balancing act among a matrix of physicochemical attributes, interaction profiles, and long-term stability, as well as regulatory acceptability and manufacturing constraints. In the classic approach to development, the result is often trial-and-error.
electing the right excipient isn’t just about flow or compressibility. It’s about balancing a complex network of physicochemical properties, interaction profiles, and long-term stability, all while considering regulatory acceptability and manufacturing constraints.
In traditional development, this process often resembles trial-and-error. But AI is turning this paradigm on its head.
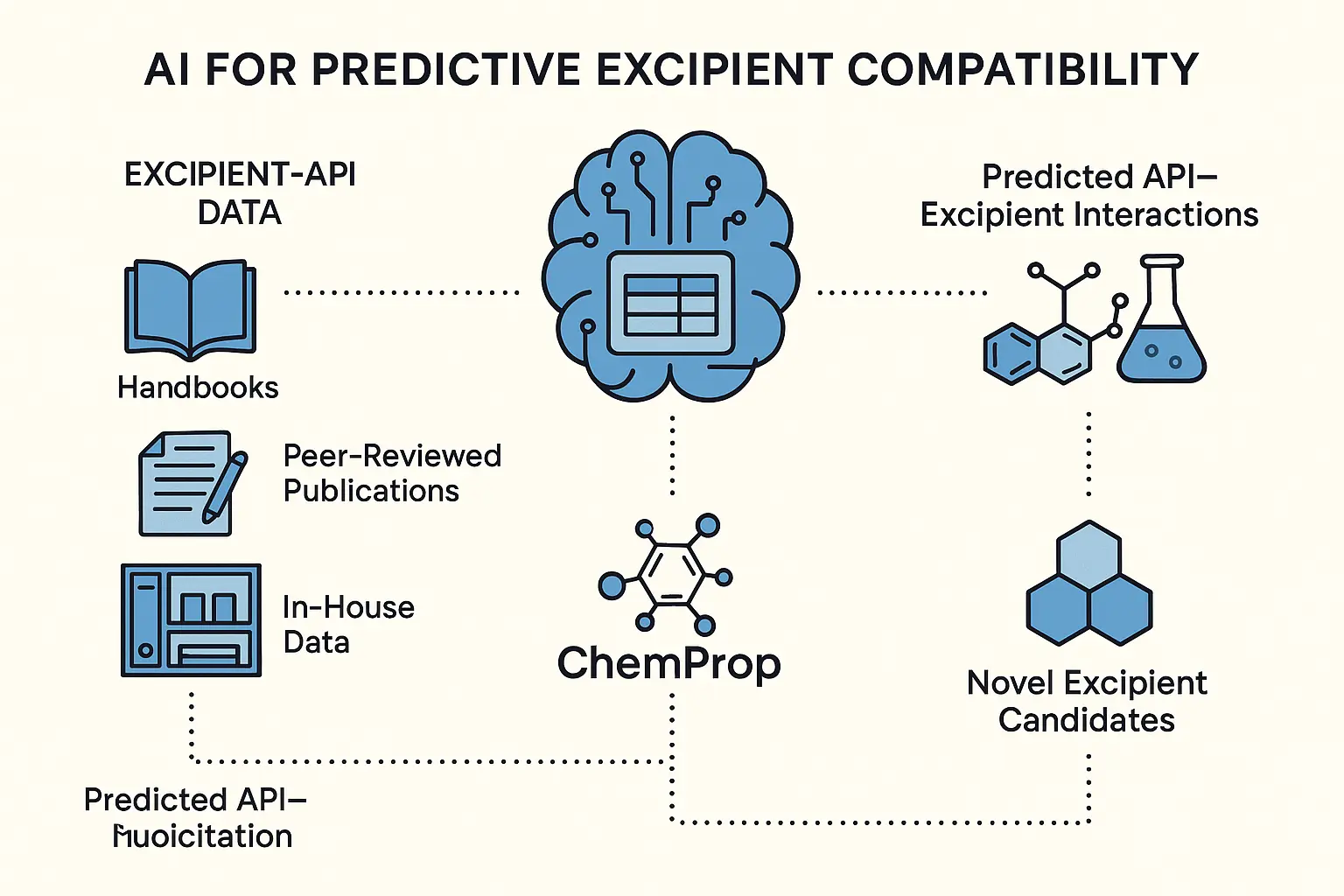
1.2 AI for Predictive Excipient Compatibility
One of the most time-consuming and failure-prone stages in drug formulation is the screening and selection of excipients. Traditionally, formulators rely on past experience, excipient handbooks, and empirical testing to identify compatible excipient-API combinations. However, with the explosion of available excipients and growing complexity of APIs, especially poorly soluble, unstable, or highly potent ones, this manual approach is increasingly inefficient and limited in scope.
Now, AI is redefining this process.
The Power of Predictive Modeling Imagine a machine learning model trained on decades of excipient–API interaction data, sourced from historical formulations, pre-formulation studies, pharmacopeial databases, internal R&D archives, and even published case failures. These models are no longer theoretical: tools like DeepChem, ChemProp, and MolBERT are now actively being deployed to predict excipient compatibility with remarkable precision.
These algorithms use features such as:
- Molecular descriptors (e.g., logP, topological polar surface area, dipole moment)
- Fingerprint-based similarity (e.g., ECFP4, MACCS keys)
- Excipient-specific properties (e.g., hygroscopicity, melting point, HLB value, functional class)
- Stability trend data under stress and ambient conditions
The result is a system capable of multi-dimensional compatibility predictions, not only checking for likely physical and chemical stability, but also flagging potential risks like moisture sensitivity, pH-dependent degradation, oxidative stress, and amorphous instability.
Sophisticated algorithms predict the most suitable excipients for a specific API, by mining chemical structure and physicochemical properties. They can even identify previously overlooked excipient candidates by mapping structural analogues and compatibility patterns.
What Makes This a Game Changer?
- API-Centric Formulation Design: Instead of screening excipients one by one, formulators can input the chemical structure or SMILES string of an API and receive a ranked list of excipients most likely to be compatible, both functionally and chemically.
- De-risking Early Formulation Decisions: AI models can flag excipients that may cause incompatibilities before they ever reach the lab bench-saving weeks of stability testing and multiple rounds of failed development.
- Discovering Hidden Candidates: Structural analog modeling allows these tools to suggest previously overlooked or underused excipients by identifying analogues with favorable compatibility patterns, even when they’re not common in commercial databases.
For example, an AI model may suggest that co-povidone, often used in solid dispersions, could be an effective stabilizer for a thermolabile API, based on its hydrogen bonding potential and past performance with chemically similar compounds, even if it’s not typically used in that context.
Real-World Applications
Companies are now building internal predictive compatibility platforms using open-source and proprietary data combined with tools like ChemProp or DeepChem. These platforms can:
- Recommend GRAS or IIG-listed excipients based on API sensitivity and route of administration
- Score excipients based on potential for Maillard reactions, peroxide formation, or polymorphic interference
- Integrate with formulation databases to automate excipient selection for both IR and ER formulations
By reducing reliance on trial-and-error and enabling a data-driven formulation design process, AI is revolutionizing excipient selection, transforming it from a bottleneck into a strategic advantage. In the near future, predictive compatibility models will likely become a standard component of QbD frameworks and CMC packages, supported by regulators as part of evidence-based formulation design.
1.3 Case Study: AI-Based Excipient Prediction for a BCS Class II Drug
A mid-size European pharmaceutical company faced a persistent challenge with the formulation of a BCS Class II API, a compound with inherently low aqueous solubility and moderate permeability. Traditional formulation strategies, including basic salt formation and micronization, had limited success. To avoid further resource drain, the company deployed an AI-based Bayesian optimization model to streamline excipient selection.
The AI Model in Action: The model was trained on a proprietary dataset of historical solubility enhancement trials across similar compounds. Key input parameters included:
- API logP, pKa, melting point
- Excipient physicochemical profiles
- Desired dissolution targets in SGF and SIF
- Stability data under accelerated conditions
By combining Bayesian optimization with Gaussian process regression, the model continuously refined its predictions based on prior excipient-performance outcomes. It was not only ranking candidates but also learning from subtle excipient-API interaction patterns, proposing combinations that would be overlooked using conventional DoE or trial-and-error methods.
The Proposed Combination: The algorithm ultimately recommended a ternary matrix of:
- Mannitol – for its hydrophilic carrier properties and taste masking
- MCC PH 102 – for its compressibility and controlled-release synergy
- Poloxamer 407 – as a nonionic surfactant to improve wetting and solubilization
This combination was unconventional, poloxamer wasn’t previously considered due to past incompatibility with a different API class. However, AI correctly identified its unique fit based on the molecular similarity of the target compound.
Measureable Outcomes
- Solubility increased by 3.4-fold in simulated intestinal fluid (SIF)
- Degradation reduced by 27% under accelerated stability (40°C/75% RH) vs. previous excipient trials
- Formulation time reduced from 7 months to under 3 months
- The new matrix also exhibited improved flowability, which supported high-speed tableting without capping or sticking.
Broader Impact:
Beyond formulation success, this project established a scalable internal workflow for AI-guided excipient screening. The team later applied a similar model to two additional BCS Class II APIs, cutting development timelines and reducing dependency on external formulation consultants.
This case illustrates how AI is not replacing formulation expertise, but enhancing human decision-making by surfacing hidden excipient synergies, compressing timelines, and reducing formulation risk. For companies working on complex or solubility-limited drugs, integrating such intelligent systems can shift formulation from reactive to predictive science.
1.4 Benefits for Industry
The integration of Artificial Intelligence into pharmaceutical formulation is rapidly becoming not just a technological edge, but a competitive necessity. Companies that strategically adopt AI across their formulation workflows are experiencing accelerated development, deeper scientific insight, and stronger market performance. These benefits are measurable, multi-dimensional, and growing in value year over year.
- Reduced Formulation Failures: AI-driven simulations and predictive modeling have helped companies reduce formulation failure rates by over 40%, based on internal audits. This translates to fewer batch reworks and faster tech transfers.
- Excipient-API Compatibility Prediction: Machine learning tools flag potential excipient incompatibilities early, without requiring extensive lab testing, saving both time and costly API material.
- Accelerated ANDA & NDA Submissions: AI-integrated QbD frameworks improve dossier quality, support stronger design space justifications, and can speed up regulatory reviews by offering transparent, data-backed rationales.
- Faster Time-to-Market: Virtual experiments and rapid optimization reduce formulation timelines by 30–50%, giving companies a first-to-file or first-to-launch advantage.
- Cost & Resource Efficiency: Fewer lab trials, reduced API usage, and smarter decision-making lead to significant cost savings—especially during early-stage development.
- Sustainability Gains: AI helps select greener excipients and optimize processes to lower energy and solvent use, aligning formulation pipelines with environmental goals.
2. Predictive Dissolution Modelling: From Wet Lab to Simulated Reality
2.1 The Power of IVIVC + AI
Traditionally, predicting how a drug releases in vivo requires months of in vitro-in vivo correlation (IVIVC) studies. AI offers a shortcut—by analyzing historical datasets and constructing robust predictive models, researchers can now simulate dissolution behavior before a single tablet is pressed.
This fusion of AI and IVIVC creates a powerful paradigm shift:
- It enables early formulation screening by simulating likely dissolution outcomes across various pH levels, agitation conditions, and polymer matrices.
- It dramatically reduces the dependency on empirical wet-lab testing, freeing up lab resources and reducing consumables and waste.
- Formulation robustness improves by allowing predictive modeling of performance in bio-relevant media, even for BCS class II and IV compounds.
- Iterative design becomes faster and smarter model-based feedback can guide minor changes to excipient levels or compression force before a single trial batch is made.
- Most importantly, AI allows for quantifiable risk assessment, by applying probabilistic frameworks (like Bayesian models), teams can predict not only what will happen, but how likely it is to happen.
By integrating these capabilities into early-stage development, formulators can optimize drug delivery profiles tailored to specific patient needs, reduce development costs, and confidently move forward with candidate formulations.
2.2 How It Works
- Supervised ML Models (e.g., XGBoost, SVM): These are trained using large sets of historical dissolution profiles and formulation variables—such as excipient ratios, tablet hardness, and granulation type. Once trained, they can accurately forecast dissolution behavior of new formulations.
- Deep Learning Networks: Especially convolutional and recurrent neural networks, can capture subtle non-linear relationships between formulation attributes and time-dependent release behavior. For instance, they can learn to predict complex biphasic or zero-order release patterns, which traditional linear models often fail to capture.
- Bayesian Inference: Goes beyond simple prediction by providing confidence intervals around each outcome, offering a layer of predictive reliability that regulators value. Bayesian models are particularly useful in scenarios where data is sparse or noisy.
- Reinforcement Learning (RL): Emerging AI techniques such as RL are now being explored to optimize dissolution profiles by iteratively improving upon formulation parameters, similar to how AI learns to master complex games. This is experimental but highly promising for real-time adaptive formulation design.
Together, these tools form an integrated AI engine that can be calibrated using proprietary lab data, scaled across multiple dosage forms, and tuned for specific regulatory goals (e.g., target release profile within a USP-specified range).
2.3 Application Example: HPMC Matrix Tablets
MIT’s Department of Chemical Engineering published a model that could predict the dissolution rate of HPMC K100 matrices across varying pH and agitation rates. Accuracy? Within ±5% of lab-tested values.
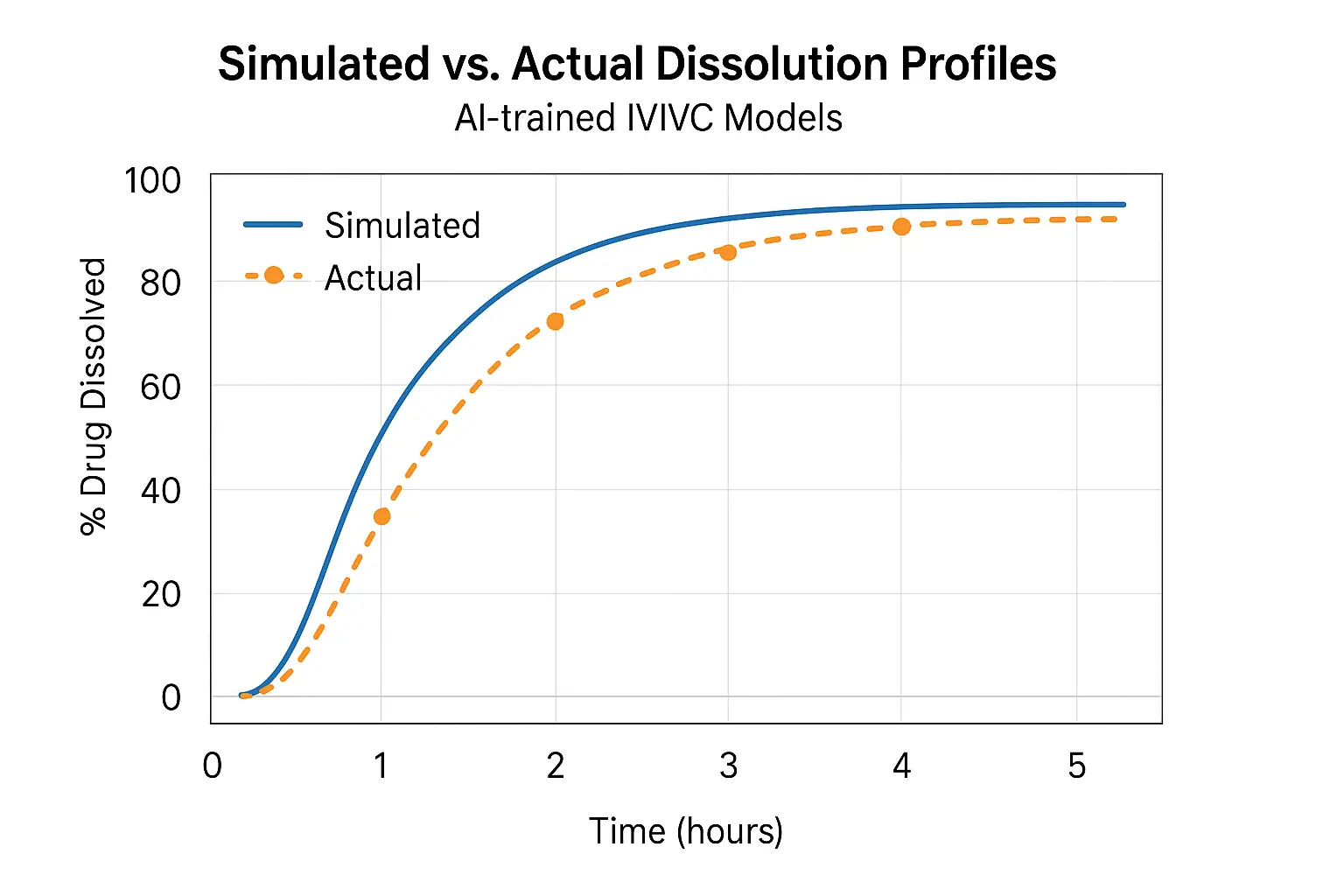
2.4 Real-World Use: From Formulation to Filing
Pfizer used AI to develop an extended-release formulation that met its 6-hour release window, cutting 4 months of lab time. Their QbD (Quality by Design) documentation included AI-derived simulations, something increasingly accepted by regulatory agencies.
2.5 Benefits
- Predicts performance before pilot batches: Formulators can virtually test dozens of formulation prototypes using AI-simulated dissolution curves, dramatically reducing the time and cost of physical trials.
- Reduces bioequivalence trial risk: By narrowing the window of uncertainty around dissolution variability, AI-based models can reduce the likelihood of clinical trial failure due to suboptimal release behavior.
- Optimizes polymer and excipient ratios: Instead of trial-and-error optimization, AI can suggest the ideal proportion of matrix formers, binders, and disintegrants based on target release profiles.
- Supports faster regulatory review: AI-generated dissolution predictions can supplement or even partially replace empirical data, especially in Model-Informed Drug Development (MIDD) frameworks, accelerating regulatory timelines.
- Enhances formulation robustness across manufacturing scales: AI models can account for scale-up variables, such as compression force or granule size distribution, ensuring performance is consistent from pilot to commercial batches.
- Integrates seamlessly with QbD and PAT tools: By acting as an analytical bridge between experimental results and process controls, AI supports real-time formulation adjustments and more resilient batch outcomes.
3. Digital Twins and Real-Time Process Optimization
3.1 What Are AI-Powered Digital Twins in Drug Formulation?
AI-Powered Digital Twins in Drug Formulation is a virtual replica of a physical process, equipment, or system that uses real-time data and AI to simulate, predict, and optimize performance. In pharmaceutical formulation, digital twins are rapidly emerging as a transformative tool for process understanding and control.
These AI-driven models integrate data from PAT (Process Analytical Technology), sensors, and historical performance to simulate operations such as blending, granulation, drying, and tablet compression. Unlike static process models, digital twins continuously evolve with every new data point, providing real-time insight into process variability, drift, and out-of-spec risks.
The application of digital twins enables:
- Dynamic process monitoring: By detecting micro-level changes in torque, moisture, or particle size, digital twins preemptively flag potential deviations.
- Predictive fault diagnosis: The model can simulate what might happen if machine settings are altered or raw material quality changes, offering a safer, faster route to optimization.
- Scalable experimentation: Dozens of virtual batches can be simulated in hours, allowing companies to test process parameters or formulation variants without occupying pilot plant resources.
3.2 Real-Time Release Testing (RTRT)
Real-Time Release Testing, or RTRT, leverages digital twins and AI to monitor and predict critical quality attributes (CQAs) in real time, moving away from traditional end-of-batch testing. This paradigm shift is especially powerful in continuous manufacturing environments.
AI-enabled RTRT uses inline sensors and multivariate data analysis (MVDA) to assess hardness, content uniformity, and dissolution rates. Models trained on historical and real-time data allow predictive decision-making about whether a batch meets predefined quality standards without waiting for offline lab assays.
- Accelerated release timelines: Quality confirmation happens in-process, enabling faster product availability.
- Reduced batch rejections: Early detection of trends like compression anomalies or granule segregation prevents batch failure.
- Regulatory alignment: Both FDA and EMA are supporting RTRT under QbD and PAT frameworks, making its adoption a competitive differentiator.
For example, a multivariate model in a rotary tablet press can predict the final dissolution profile by analyzing compression force, dwell time, tablet weight, and lubricant distribution in real-time.
3.3 Case Study: Continuous Manufacturing Unit with AI-Integrated Digital Twins
A multinational CDMO implemented AI-powered digital twins in their roller compaction and blending units as part of a continuous manufacturing initiative. By feeding real-time data (e.g., granule size distribution, feed screw torque) into a neural network model, they could adjust system parameters like compaction force or blending speed within seconds.
Results included:
- 27% increase in overall equipment effectiveness (OEE)
- 60% reduction in out-of-specification (OOS) batches
- 30% decrease in energy consumption through real-time optimization of drying parameters
Moreover, their digital twin allowed operators to run “what-if” simulations, e.g., testing different excipient sources or responding to a sudden humidity spike, without halting production.
This case illustrates how digital twins are no longer futuristic concepts, they are operational assets that combine AI, IoT, and pharma process engineering into one dynamic decision-making engine.

4. Integration with QbD and Regulatory Strategy
4.1 QbD Meets AI
Quality by Design (QbD) is grounded in the principle of building quality into the product from the outset by understanding the product and process variables. When AI is introduced into QbD frameworks, the synergy is profound. Instead of relying solely on a predefined Design of Experiments (DoE), AI models can adaptively learn from each experimental run, refining hypotheses and reducing the number of required iterations.
This means that the Critical Quality Attributes (CQAs), Critical Material Attributes (CMAs), and Critical Process Parameters (CPPs) can be more precisely predicted and validated. For instance, using historical batches and lab trials, AI can pinpoint the narrowest design space for a target dissolution rate, thereby minimizing waste and variability. AI transforms QbD from a structured process into a dynamic, real-time learning system.
4.2 Regulatory Landscape
Regulatory bodies such as the FDA and EMA are no longer passive observers of AI, they are active participants shaping its integration into the pharmaceutical lifecycle. The FDA’s Model-Informed Drug Development (MIDD) Pilot Program explicitly supports the use of machine learning models for dose selection, formulation design, and even bioequivalence simulations. This opens the door for AI-derived models to be used not just in internal R&D but also as part of regulatory submissions.
The EMA’s 2023 “Reflection Paper on AI” goes further, laying out expectations for algorithm transparency, explain-ability, training dataset traceability, and version control. These frameworks suggest a future where validated AI models could play a core role in risk assessments, post-marketing surveillance, and even real-time batch release protocols.
AI models are now being referenced in CTD Module 3 under pharmaceutical development. Inclusion of algorithm outputs, model confidence scores, and model validation metrics is gradually becoming a new norm in dossier documentation.
4.3 The Prime Regulatory Concerns
Despite growing regulatory openness, several critical concerns remain at the forefront:
- Traceability of Training Data: Regulators expect full transparency about where the training data for AI models comes from, how it was curated, and whether it represents a diverse enough set of examples to be robust across geographies and manufacturing scales.
- Model Validation Under GMP Conditions: AI models must demonstrate repeatability and reliability under Good Manufacturing Practice (GMP). This involves not just technical validation, but also procedural controls, like ensuring the same model produces consistent outcomes when integrated into batch processing.
- Algorithm Version Control and Audit Trails: Changes to the AI model, whether retraining, reweighting, or updating datasets must be tracked, documented, and justified. This is akin to maintaining source control in software development and is critical for both internal compliance and external audits.
- Explain-ability: Models that function as ‘black boxes’ are problematic. Regulatory bodies are pushing for models that can offer interpretable outputs. Explain-ability tools like SHAP (Shapley Additive Explanations) and LIME (Local Interpretable Model-agnostic Explanations) are being explored to meet this demand.
Together, these concerns are not roadblocks but guideposts, pushing pharmaceutical companies to adopt AI in a way that is scientifically sound, ethically responsible, and operationally transparent.
5. Ethical and Practical Limitations
5.1 Bias in Datasets
AI is only as good as the data it is trained on. In pharmaceutical formulation, this becomes a glaring vulnerability when datasets used to train models are heavily skewed toward commonly studied APIs or legacy excipients. For example, if a model has been primarily trained using formulations centered around BCS Class I APIs, it may perform poorly when applied to the more challenging BCS Class II or IV compounds.
This bias isn’t just a technical flaw, it has downstream impacts:
- Skewed recommendations: AI may disproportionately favor “safe” excipients that have been over-represented in past successful formulations, thereby stifling innovation.
- Exclusion of novel excipients: Cutting-edge excipients with limited historical data may be overlooked entirely, even if they offer superior bioavailability or stability benefits.
- Regulatory blind spots: If datasets are geographically or regulatorily biased (e.g., predominantly FDA-approved data), models may underperform in EMA or PMDA submissions due to divergent excipient acceptability standards.
To mitigate this, formulators and data scientists must collaborate to curate diverse, well-annotated, and representative datasets. Cross-institutional data-sharing platforms, anonymized trial repositories, and regulatory harmonization of data standards can help build more inclusive training libraries.
5.2 Explain-ability vs. Performance
One of the most contentious trade-offs in AI is between model accuracy and interpretability. Deep learning models, especially those using convolutional or recurrent neural networks, often outperform traditional statistical models in terms of predictive power. But they do so at a cost: they are black boxes.
In pharmaceutical formulation, where every decision must be justifiable to regulators, clinicians, and internal stakeholders, this lack of transparency can be a dealbreaker. Consider the following dilemmas:
- A neural network predicts a particular excipient combination will yield optimal dissolution, but can’t explain why.
- Regulators request scientific rationale behind model recommendations, but the algorithm provides none.
Emerging solutions to this challenge include:
- Model-agnostic explanation tools such as SHAP (Shapley Additive Explanations), which quantify the contribution of each input feature to the final prediction.
- Surrogate models like decision trees that approximate black-box models for interpretive purposes.
- Hybrid AI architectures where interpretable layers (e.g., linear regression) are used in early stages before deeper layers refine predictions.
Ultimately, the future belongs to explainable AI (XAI), models that balance sophistication with clarity, and accuracy with accountability.
5.3 Skills Gap
Perhaps the most underdiscussed barrier to AI adoption in formulation is the human one: the widening skills gap. Traditional formulation scientists are experts in physical chemistry, pharmacokinetics, and regulatory science—but not necessarily in data modeling, Python programming, or neural network architecture.
This divide leads to two major consequences:
- Underutilization of AI tools due to lack of confidence or understanding.
- Overreliance on data scientists who may lack contextual pharmaceutical knowledge, leading to suboptimal model training and interpretation.
Bridging this gap requires a deliberate shift in professional development:
- Cross-disciplinary training programs where formulators learn coding fundamentals and data scientists are taught formulation basics.
- Internal “AI Champions” within formulation teams who serve as translators between scientific and computational domains.
- User-friendly AI platforms with intuitive interfaces, guided modeling workflows, and built-in regulatory compliance modules.
The goal isn’t to turn every formulator into a machine learning engineer, but to empower them to speak the language of AI fluently enough to lead its application wisely and responsibly.
Conclusion: The Human-AI Partnership in Formulation Science
AI will not, and should not, replace the brilliance of the human mind. What it will do is exalt the role of the formulator from a trial-and-error technician to a strategic innovator. It empowers scientists to look beyond the petri dish and the HPLC report, to see patterns invisible to the naked eye, to simulate what hasn’t yet been created, and to engineer solutions that solve real patient needs faster and smarter. The power of future AI extends far beyond the boundaries of scientific imagination.
The real revolution isn’t just in the code, t’s in the collaboration. When data-driven intelligence meets human curiosity, something magical happens: science evolves. It’s no longer about keeping up with timelines or tweaking one variable at a time. It’s about unleashing a new era of formulation design where insights are instantaneous, risks are calculated, and possibilities are endless.
To the formulation scientists reading this: AI isn’t your competitor, it’s your co-pilot. Use it. Train it. Question it. But above all, lead it. Because the future of pharma won’t be written by machines alone, it will be written by people like you, bold enough to reimagine what’s possible.
And if you do that, the applause won’t just come from your team or your regulators. It will come from the patients whose lives were made better, because you chose to innovate, not imitate.
References
- EMA (2023). Reflection Paper on the Use of Artificial Intelligence (AI) in the Medicinal Product Lifecycle. European Medicines Agency.
- FDA (2023). Model-Informed Drug Development Pilot Program. U.S. Food and Drug Administration.
- GSK R&D (2023). Transforming Drug Manufacturing Using Predictive Models and Digital Twins. ISPE Annual Conference.
- ISPE (2022). Digital Twins in Pharma: A Practical Framework for Deployment.
- Jommi, C., & Lauria, A. (2023). Artificial Intelligence in Pharmaceutical Development. Journal of Pharmaceutical Innovation, 18(2), 112–130.
- Lee, C. Y., & Weng, C. (2023). Addressing the Skills Gap in AI-Driven Drug Formulation. AI in Healthcare Review, 9(1), 45–59.
- Lundberg, S. M., & Lee, S. I. (2017). A Unified Approach to Interpreting Model Predictions. NeurIPS Proceedings.
- MIT Department of Chemical Engineering (2022–2024). Technical Reports on AI in Controlled Release Formulations.
- Molnar, C. (2022). Interpretable Machine Learning: A Guide for Making Black Box Models Explainable. Leanpub.
- Pfizer (2022). Internal Whitepaper: AI-Enabled Extended Release Development and Submission Efficiency.
- Sahoo, S., & Rai, R. (2021). Reducing AI Bias in Pharmaceutical Data Science. Pharmaceutical Data Intelligence, 5(3), 220–234.
- SHAP & LIME GitHub (2024). Open-source explainability frameworks. https://github.com/slundberg/shap / https://github.com/marcotcr/lime
- Tiwari, R., Agarwal, R., & Singh, A. (2021). Machine Learning Models for Predictive Dissolution Profiling. International Journal of Pharmaceutics, 599, 120417.
- Zhang, Y., et al. (2020). Applications of Deep Learning in Drug Formulation Development. Drug Discovery Today, 25(11), 1872–1883.